من واقع تجربة مؤرِّقة: ما العمل إذا قوبلت أطروحتك بالرفض؟
12 November 2024
نشرت بتاريخ 5 سبتمبر 2024
مع الانفجار الكبير لتقنيات الذكاء الاصطناعي التوليدي وتطبيقاته في مجالات الكتابة، تتبادر إلى الأذهان تساؤلات صعبة حول ما يجوز وما لا يجوز في استخدام هذه التقنيات.

من الاتهامات التي طاردت رئيسة جامعة هارفارد ودفعتها إلى الاستقالة في يناير الماضي، إلى الكشف في فبراير عن أجزاء منتحَلة في تقارير تحكيم الأوراق العلمية: حالةٌ من الاضطراب تضرب المؤسسات الأكاديمية حول العالم على أثر تفشِّي السرقات العلمية.
وإذا كانت هذه المشكلة تشمل عديد المجالات، فإنها في مجال الكتابة العلمية أدهى وأمرّ. فالإقبال الهائل، وبسرعةٍ لافتة، على أدوات الذكاء الاصطناعي التوليدي — التي تُنتج نصوصًا استنادًا إلى ما تتلقَّى من توجيهات — أثار عاصفةً من التساؤلات حول ما إذا كان استخدام هذه الأدوات يمثل سرقة علمية، والحالات التي يجوز فيها السماح بها. يقول جوناثان بيلي، المتخصص في تقديم الاستشارات بشأن حقوق الملكية والسرقة العلمية، ويُقيم في مدينة نيو أورلينز بولاية لويزيانا الأمريكية، إن "نطاق استخدامات الذكاء الاصطناعي شديد الاتساع، نجد عند أحد طرفيه الكتابة البشرية التي لا يخالطها من الذكاء الاصطناعي شيء، وعند الطرف الآخر النصوص المولَّدة بكاملها بالذكاء الاصطناعي، وبين هذين النقيضين نجد مساحة شاسعة من الالتباس".
صحيحٌ أن أدوات الذكاء الاصطناعي، من قبيل «تشات جي بي تي» ChatGPT، القائمة على خوارزميات تُعرف بالنماذج اللغوية الكبيرة (LLMs)، يمكن أن توفر الوقت، وتجعل النصوص أوضح، وتقلل الفجوة الناشئة عن العوائق اللغوية. وهناك كثرة من الباحثين الذين يرون ألا ضير في الاستعانة بها في ظروف بعينها، شريطة الإفصاح عن استخدامها بشكلٍ واضح لا لبس فيه.
إلا أن مثل هذه الأدوات تصبُّ زيتًا على نار الجدل المستعر أصلًا حول الاستخدام غير الحصيف لأعمال الآخرين. ذلك أن تدريب النماذج اللغوية الكبيرة على توليد النصوص إنما يكون بتزويدها بكمياتٍ هائلة من النصوص المنشورة سلفًا. ومن هنا، فإن استخدام هذه النماذج ربما ينطوي على سرقة أو ما يشبه السرقة: إذا ما قدَّم الباحث منتوج أداة الذكاء الاصطناعي على أنه من تأليفه، مثلًا، أو إذا أنتجت هذه الأداة نصًّا شديد الشبه بنَصٍّ موجود بالفعل، دون إشارة إلى المصدر. وقد تُستخدم هذه الأدوات أيضًا في التعمية على السرقة العلمية المتعمَّدة، ويكون استخدامها لهذا الغرض عسيرًا على الكشف. يقول بيتي كوتون، عالم النُّظم الإيكولوجية بجامعة بليماوث الإنجليزية: "سيكون من الصعب، والصعب جدًا، تحديد ما يندرج في خانة عدم الأمانة العلمية أو السرقة العلمية، ومن ثم وضع الحدود التي لا ينبغي تجاوزها".
في دراسة مسحية أُجريَت في عام 2023، وشملت 1,600 باحث، أفاد 68% من المشاركين أن الذكاء الاصطناعي سيجعل السرقة العلمية أيسر، وأصعب على الكشف. وقد علَّقت ديبورا فيبر-فولف، المتخصصة في السرقة العلمية بجامعة العلوم التطبيقية في برلين، قائلة: "الجميع قلقون من استخدام غيرهم لهذه الأنظمة، وقلقون من ألا يستخدموا هم هذه الأنظمة عندما يجدُر بهم ذلك. الحيرة تنتظم الجميع بمعنًى من المعاني".
سرقة علمية معزَّزة بالذكاء الاصطناعي
السرقة العلمية (plagiarism)، حسب تعريف المكتب الأمريكي للنزاهة البحثية، هي "الاستيلاء على أفكار شخص آخر، أو إجراءاته، أو نتائجه، أو كلماته دون نسبتها إليه بشكل سليم". تشير دراسة نُشرت في عام 2015 إلى أن 1.7% من العلماء أقرُّوا بإقدامهم على السرقة العلمية، وأن 30% منهم يعرفون زملاء لهم ارتكبوا هذا الجُرم البحثي1.
الوضع في وجود النماذج اللغوية الكبيرة يمكن أن يكون أسوأ. فليس أسهل من التعمية عن السرقة المتعمَّدة من نص بشري: كل ما على المستخدم في هذه الحالة هو أن يطلب إلى النموذج أن يُغيِّر الصياغة. ويقول محمد عبد المجيد، الباحث في علوم الحاسب واللغويات بجامعة كولومبيا البريطانية في فانكوفر، بكندا، إن هذه الأدوات يمكن أن توجَّه بحيث تعيد الصياغة بطُرُق أكثر تركيبًا، كأن تحاكي أسلوب الكتابة في دورية أكاديمية.
في القلب من هذه القضية سؤال عما إن كان النص المولَّد بالكامل عبر تقنيات الذكاء الاصطناعي، وغير المنسوب إلى مصدر، يقع تحت طائلة السرقة العلمية. وإجابة كثير من الباحثين هي: ليس بالضرورة. من ذلك، مثلًا، أن التوصيف الذي وضعته الشبكة الأوروبية للنزاهة الأكاديمية، التي تضم في عضويتها جامعات وأفرادًا، للاستخدام الممنوع أو غير المُفصَح عنه لأدوات إنتاج النصوص القائمة على الذكاء الاصطناعي هو: "توليد المحتوى بطريقة غير مصرَّح بها"؛ ما يعني أنها لم تجزم بأن هذا مما يدخل في باب السرقة العلمية2. وتقول فيبر-فولف: "السرقة العلمية، من وجهة نظري، هي سرقة أشياء يمكن نسبتها إلى شخص آخر معلوم". وذكرت أنه على الرغم من وجود أمثلة على إنتاج أدوات الذكاء الاصطناعي التوليدي نصوصًا مطابقةً أو تكاد لنصوص بشرية منشورة سلفًا، إلا أن النصوص المولَّدة بالذكاء الاصطناعي لا تحمل — في غالب الأحيان — هذا الشبه الكبير الذي يصحُّ معه دمغها بالسرقة العلمية.
ومن جهة أخرى، يذهب البعض إلى أن أدوات الذكاء الاصطناعي التوليدي تنتهك حقوق الملكية الفكرية. والسرقة العلمية وانتهاك حقوق الملكية كلاهما ينطويان على الاستخدام غير السليم لإنتاج الغير؛ إلا أن السرقة تُعد خروجًا عن الأخلاقيات الأكاديمية، أما انتهاك حقوق الملكية الفكرية فقد يُعد خرقًا للقانون. وفي هذا الصدد، ذكرت رادا ميهالشا، الباحثة في علوم الحاسب بجامعة ميشيجان في مدينة آن آربور الأمريكية: "أنظمة الذكاء الاصطناعي هذه مبنية على عمل الملايين أو مئات الملايين من البشر".
وقد احتجَّ عدد من المؤسسات الإعلامية وآحاد المؤلفين على ما يرون أنه انتهاكٌ لحقوق الملكية الفكرية من قِبل أنظمة الذكاء الاصطناعي. ففي ديسمبر من عام 2023، رفعت صحيفة «ذا نيويورك تايمز» دعوى قضائية ضد شركة التكنولوجيا العملاقة «مايكروسوفت»، وشركة «أوبن إيه آي» Open AI، وهي الشركة الأمريكية التي تقف وراء النموذج اللغوي الكبير المسمَّى «جي بي تي-4» GPT-4، الذي يقوم عليه ربوت الدردشة «تشات جي بي تي». في هذه القضية المنظورة أمام المحاكم الأمريكية، ادَّعت الصحيفة على الشركتين المشار إليهما أنهما نَسَختا الملايين من مقالاتها لتغذية النماذج اللغوية الكبيرة، التي باتت تنافس الصحيفة فيما تقدم من مواد صحفية. واشتملت الدعوى على أمثلةٍ على توجيهات بعينها، عند إدخالها إلى النموذج «جي بي تي-4»، يُنتج العديد من الفقرات المنقولة من مقالات الصحيفة نقلًا حرفيًّا أو يكاد.
وفي فبراير الماضي، تقدَّمت شركة «أوبن إيه آي» بطلب إلى محكمة فيدرالية تنفي فيه جوانب من الادعاء، زاعمةً أن "«تشات جي بي تي» لا يُعدُّ بحالٍ من الأحوال بديلًا للاشتراك" في الصحيفة. وذكر متحدث باسم شركة «مايكروسوفت» أنه "يتعين إفساح المجال أمام تقدُّم الأدوات العاملة بالذكاء الاصطناعي، والمطوَّرة بصورة قانونية، ما دامت تتوخَّى في تقدُّمها مسلكًا مسؤولًا"، مضيفًا أن هذه الأدوات "ليست بديلًا للدور الحيوي الذي ينهض به الصحفيون".
يرى بيلي أنه إذا قضت المحكمة بأن تغذية أنظمة الذكاء الاصطناعي بالنصوص دون الحصول على إذن أصحابها يُعد انتهاكًا لحقوق الملكية الفكرية، "فسوف يمثل ذلك صفعة كبرى لشركات الذكاء الاصطناعي". وتابع قائلًا إنه من دون التدريب على المواد النصية بكميات ضخمة، فإن أداةً مثل «تشات جي بي تي» "لن يكون لها وجود".
الذكاء الاصطناعي: الانفجار العظيم
سواءٌ أكان سرقة علمية أم لم يكن، الثابت أن استخدام الذكاء الاصطناعي قد انتشر في الكتابة الأكاديمية انتشار النار في الهشيم منذ انطلاق «تشات جي بي تي» في نوفمبر من عام 2022.
في مسوَّدة بحثية نُشرت في يوليو الماضي3، قدَّر الباحثون أن النماذج اللغوية الكبيرة استُعملت فيما لا يقل عن 10% من ملخصات الأبحاث الطبية البيولوجية خلال الشهور الستة الأُوَل من عام 2024 (ما يعادل نحو 150 ألف ورقة في العام). حلَّل الباحثون، يقودهم عالم البيانات بجامعة توبنجن الألمانية ديمتري كوباك، نحوًا من 14 مليون ملخص بحثي في قاعدة البيانات الأكاديمية «بَب مِد» PubMed، نُشرت بين عامي 2010 و2024. وأبان الباحثون كيف أن ظهور النماذج اللغوية الكبيرة ارتبط بزيادة في استخدام مفردات أسلوبية أو كلمات بيانٍ بعينها، مثل الكلمة الإنجليزية "delves" (التي تقابلها في العربية كلمة: يغوص أو يتعمق)، وكلمة "showcasing" (يعرض أو يُظهر)، وكلمة "underscores" (يُبرز أو يؤكد أهمية شيء ما). ثم كان أن استندوا إلى هذه التركيبات اللغوية الغريبة في قياس نسبة الملخصات التي استُعين في إعدادها بالذكاء الاصطناعي (انظر: الذكاء الاصطناعي في الأبحاث العلمية). وانتهى الباحثون إلى أن "ظهور أدوات الكتابة القائمة على النماذج اللغوية الكبيرة له تأثير غير مسبوق في الأدبيات العلمية".
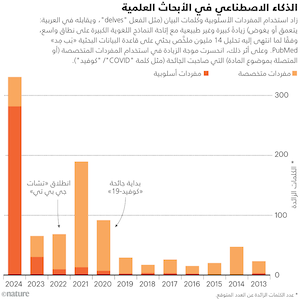
مما استرعى انتباه كوباك وفريقه أن الأبحاث التي خرجت من بلدان مثل الصين وكوريا الجنوبية تضمنت إشارات ودلائل على استخدام النماذج اللغوية الكبيرة أوضح وأشدّ كثافة منها في الأبحاث الآتية من البلدان التي تسود فيها اللغة الإنجليزية. ومع ذلك، لا يستبعد كوباك أن تكون هذه الأدوات مستعملة في أبحاث الفئة الأخيرة من البلدان بنفس الكثافة، ولكن بطُرُق أصعب على الكشف. واستخدام النماذج اللغوية الكبيرة "سيستمر في ازدياد، بكل تأكيد"، حسب توقع كوباك، الذي تابع قائلًا: "وربما يكون اكتشافه أصعب".
الاستعانة بوسائل برمجية في الكتابة الأكاديمية، دون إفصاح، ليست بالشيء الجديد. فمنذ عام 2015، وجيلوم كاباناك، الباحث في علوم الحاسب بجامعة تولوز الفرنسية، ومعه زملاؤه، منكبُّون على كشف الأوراق البحثية المحشوَّة كلامًا لا معنى له، التي ينتجها برنامج «ساي جِن» SCIgen، وكذلك الأوراق التي تحوي تعبيرات ملفَّقة، لا أصل لها، هي من صُنع تطبيقات الترجمة أو إعادة الصياغة. يقول كاباناك: "حتى قبل [ظهور] الذكاء الاصطناعي التوليدي، كان الناس يستخدمون أدوات لإبقائهم بعيدًا عن أعيُن الرُّقباء".
استخدام الذكاء الاصطناعي في الكتابة الأكاديمية ليس شرًّا كله؛ بل لا يخلو من قيمة. مِن الباحثين مَن يرى أنه يمكن أن يجعل النصوص والمفاهيم أوضح، ويساعد على تجاوز العوائق اللغوية، ويوفر للباحثين الوقت ليتفرغوا للتفكير وإجراء التجارب. تذكُر هند الخليفة، باحثة تقنية المعلومات بجامعة الملك سعود، بالعاصمة السعودية الرياض، أنه قبل أن تصبح أدوات الذكاء الاصطناعي التوليدي متاحة، كان كثيرٌ من زملائها، ممَّن يتخذون الإنجليزية لغةً ثانية، يجدون صعوبة بالغة في كتابة أوراقهم. تقول: "أما الآن، فتركيزهم مُنصبٌّ على البحث العلمي، تاركين عناء الكتابة لهذه الأدوات".
غير أن الالتباس يكون هو السمة الغالبة حين يتمخض استخدام الذكاء الاصطناعي عن سرقة علمية، أو خروج عن حيز الأخلاقيات البحثية. يرى سُهيل فايزي، الباحث في علوم الحاسب بجامعة ميريلاند، الكائنة في مدينة كوليدج بارك الأمريكية، أن توظيف النماذج اللغوية الكبيرة في إنتاج مواد عبر إعادة صياغة أوراق بحثية موجودة سلفًا يُعد سرقة علمية لا لبس فيها. أما أن يُستعان بأحد هذه النماذج بُغية المساعدة في التعبير عن الأفكار — إما بإنتاج نص قائم على توجيه (prompt) مفصَّل، أو تحرير نسخة أوَّلية مكتوبة بالفعل — فهذا مما لا ينبغي أن يُعاقَب عليه إذا تم بشفافية. يقول: "ينبغي السماح للأشخاص بالاستفادة من النماذج اللغوية الكبيرة على النحو الذي يمكِّنهم من التعبير عن أفكارهم بوضوحٍ كاف، ودون عناء".
والحق أن كثيرًا من الدوريات العلمية لديها الآن سياسات تسمح بدرجةٍ ما من الاستعانة بالنماذج اللغوية. كانت دورية «ساينس» Science قد قررت الامتناع عن قبول أي نص مولَّد باستخدام «تشات جي بي تي»، قبل أن تعود في نوفمبر من عام 2023 لتدخل تعديلًا على سياستها مفاده أن استخدام أي تقنيات قائمة على الذكاء الاصطناعي في كتابة المسوَّدات البحثية ينبغي أن يُفصح عنه إفصاحًا تامًا، بما في ذلك النظام المستخدم، والتوجيهات التي تم إدخالها للحصول على النص. وجاء في السياسة أيضًا أن المؤلفين تقع عليهم مسؤولية الدقة و"ضمان خلو [النص المقدَّم] من السرقة العلمية". وبالمثل، تنص السياسة المعمول بها في مجلة Nature على ضرورة أن يوثِّق المؤلفون أي استخدام للنماذج اللغوية الكبيرة في قسم المنهجيات من الورقة البحثية المقدَّمة للنشر بها (علمًا بأن للمجلة فريق أخبار وتحقيقات مستقلًّا تحريريًّا عن فريق الدوريات العلمية المتخصصة لديها).
في تحليلٍ شمل مئةً من كبريات دور النشر، ومئة دورية علمية مرموقة، تبيَّن أنه بحلول أكتوبر من عام 2023، كان 24% من دور النشر و87% من الدوريات قد أقرَّت قواعد منظِّمة لاستخدام الذكاء الاصطناعي.4 وجميع الدور والدوريات التي وضعت هذه القواعد، بغير استثناء تقريبًا، اتفقت على منع الإشارة إلى أداةٍ من أدوات الذكاء الاصطناعي بوصفها مؤلفًا، لكنها اختلفت على أنواع الذكاء الاصطناعي المصرَّح بها، ودرجة الإفصاح المطلوبة. وترى فيبر-فولف أننا أحوَج ما نكون إلى قواعد أوضح للتعامل لتنظيم استخدام الذكاء الاصطناعي في الكتابة الأكاديمية.
استخدام النماذج اللغوية الكبيرة في كتابة الأوراق العلمية، وإن يكن في الوقت الراهن مستشريًا إلى حدٍّ بعيد، يحدُّه شيءٌ من القصور في هذه النماذج ذاتها، على حد قول عبد المجيد. فالمستخدم يُضطر إلى إدخال توجيهات مفصَّلة، لوصف الجمهور المستهدف، والأسلوب المراد، والمستوى اللغوي، والتخصص البحثي الدقيق. وهو يرى أنه "من الصعب جدًّا على النموذج اللغوي أن يعطيك ما تريد منه تمامًا".
ومع ذلك، فكما قال عبد المجيد، ينشغل المطوِّرون الآن بالعمل على تطبيقات تسهِّل على الباحثين إنتاج مادة علمية متخصصة. فعوضًا عن كتابة توجيهات مفصلة، حسب قوله، يمكن للمستخدم مستقبلًا أن يختار – مثلًا – من قائمة منسدلة تُعدِّد الخيارات، وبضغطة زرٍ، يحصل ورقة بحثية كاملة من الصفر.
أدوات لكشف أدوات الكتابة
الإقبال السريع على النماذج اللغوية الكبيرة لكتابة النصوص صاحَبَه إقبال آخر على أدواتٍ لكشف هذه النماذج. وصحيح أن الكثير من هذه الأدوات تُفاخر بدقَّتها — التي تجاوزت 90% في بعض الحالات — إلا أن غالبية هذه الأدوات، كما تشير الدراسات، لا ترقى إلى المستوى الذي تروجِّ له. ففي دراسة منشورة في ديسمبر الماضي5، عمدت فيبر-فولف، رفقة فريقها، إلى تقييم 14 أداة من أدوات كشف الذكاء الاصطناعي المستخدمة على نطاق واسع في الحقل الأكاديمي. وجد الباحثون أن خمس أدواتٍ فقط هي ما نجحت (بدقةٍ بلغت 70% أو أكثر) في تحديد ما إن كانت النصوص بشريةً أم مولَّدة بالذكاء الاصطناعي، وأن أيًّا من الأدوات موضع البحث لم يتخطَّ حاجز الـ80%.
تراجعت دقة أدوات الكشف إلى ما دون الـ50%، في المتوسط، عند إدخال تعديلات طفيفة على النص المولَّد بالذكاء الاصطناعي، كأن تُستبدل بالكلمات مرادفاتها، أو يُعاد ترتيب الجُمَل. يقول مؤلفو الدراسة إن "نصًّا كهذا يتعذَّر كشفه تقريبًا بالأدوات المتاحة حاليًّا". وأظهرت دراسات أخرى كيف أن تغيير صياغة النص الواحد بالذكاء الاصطناعي عدة مرات كفيل بأن يهبط بدقة أدوات الكشف بشكل ملحوظ6.
وثمة مشكلات أخرى تعتري عمل أدوات الكشف عن الذكاء الاصطناعي. أشارت إحدى الدراسات، مثلًا، إلى ارتفاع احتمالات خطأ هذه الأدوات في تصنيف النصوص المكتوبة بالإنجليزية (دامغةً إياها بأنها نصوص مولَّدة بالذكاء الاصطناعي، خلافًا للحقيقة) إذا كان أصحاب هذه النصوص ليسوا من أهل اللغة الإنجليزية7. ويقول فايزي إنه لا يمكن الوثوق في تمييز أدوات الكشف هذه بين الحالات التي يُكتب فيها النص بالذكاء الاصطناعي من الألف إلى الياء، وتلك التي يستعين فيها المؤلف بأدوات الذكاء الاصطناعي لأغراض التنقيح، عن طريق ضبط القواعد اللغوية وجعل الجُمَل أكثر وضوحًا. يقول: "تمييز هذه الحالات عن تلك ليس بالأمر اليسير، والنتائج لا يمكن الوثوق بها، وقد تؤدي إلى ظهور معدلات خطأ كبيرة، بالحكم على النصوص بأنها مولَّدة بالذكاء الاصطناعي على غير الحقيقة". وأضاف أن الاتهام زورًا باستخدام الذكاء الاصطناعي يمكن أن يكون له "تأثير مدمِّر على سمعة الباحثين والطلاب".
وأكبر الظن أن الحدَّ الفاصل بين الاستخدامات المشروعة وغير المشروعة للذكاء الاصطناعي لن تزيد إلا غموضًا وتشوُّشًا. في مارس من عام 2023، أعلنت شركة «مايكروسوفت» أنها شرعت في إدماج أدوات الذكاء الاصطناعي التوليدي في برامجها، مثل «وورد»، و«باوربوينت»، و«آوتلوك». وبعض الإصدارات من أداتها القائمة على الذكاء الاصطناعي، المسمَّاة «كوبايلوت» Copilot، تستطيع كتابة أو تحرير المحتوى. وفي شهر يونيو الماضي، بدأت شركة «جوجل» هي الأخرى في إدماج نموذج الذكاء الاصطناعي الذي طوَّرَتْه، ويحمل اسم «جيميني» Gemini، في خدماتها، مثل «دوكس» و«جيميل».
تقول ديبي كوتون، المتخصصة في شؤون التعليم العالي بجامعة بليماوث مارجون البريطانية: "أصبح الذكاء الاصطناعي داخلًا في كل شيء نستخدمه، حتى أنني أعتقد أنه، يومًا بعد يوم، سيكون من الصعوبة بمكان تحديد ما إن كان الشيء الذي فعلتَه متأثرًا بالذكاء الاصطناعي، أم لا. وما أرى إلا أنه سيواصل التطوُّر بسرعة لا نقدر على مواكبتها".
* هذه ترجمة للمقالة الإنجليزية المنشورة بدورية Nature بتاريخ 30 يوليو 2024.
doi:10.1038/nmiddleeast.2024.279
12 November 2024
10 November 2024
أحد الفائزين بالحائز جائزة نوبل في الفيزياء يتحدث عن حل المشاكل المتداخلة بين المجالات العلمية المختلفة: "الإنصات إلى جدال العلماء له فوائده".
07 November 2024
اشترك للحصول على النشرة الإلكترونية المحدّثة كل أسبوعين لكي تبقى على اطلاع بكافة المستجدات على الموقع.
التسجيل في خدمة النشرات الإلكترونية (بالإنجليزية)
تواصل معنا: